
Künstliche Systeme zu Texterzeugung gibt es schon lange. Allerdings waren sie lange Zeit auf wohl definierte Nischenanwendungen beschränkt oder aber von zweifelhafter Qualität. Technische Fortschritte seit Ende der 2010er Jahre haben zu den generativen Sprachmodellen (Large Language Modells, LLMs) geführt, die nun erstaunlich plausible und gut lesbare Texte erzeugen können. Schnell haben diese Systeme große öffentliche Aufmerksamkeit erfahren – durch ihre Fähigkeiten wurden sie bald als utopische Heilsbringer, bald als dystopische Untergangsmaschinen beschrieben. Hier stellen wir dir etwas weniger aufgeregte Hintergrundinformationen und prominente Kritik dazu bereit.
Basis dieser modernen KI-Systeme sind probabilistische Sprachmodelle. Probabilistik ist Teil der Stochastik, also der Wahrscheinlichkeitsrechnung (vgl. das englische Wort probably). Das heißt, dass diese Modelle nicht wie ihre Vorgänger auf festen Regeln basieren, sondern auf wahrscheinlichen Wortabfolgen. Diese lernt das Modell in einem aufwendigen Trainingsprozess durch enorme Sammlungen menschlich verfasster Texte wie Webseiten und Bücher. Je häufiger bestimmte Wort- oder Satzfragment-Abfolgen in den Trainingsdatensätzen zu finden sind, desto höher ist die Wahrscheinlichkeit, dass das Sprachmodell sie reproduziert.
Abb. 1: Die Metapher „Stochastischer Papagei“ spielt mit populären Missverständnissen über die Funktion aktueller Sprachmodelle (Large Language Modells, LLMs). Generiert von Florian Pestoni mit Midjourney (Abbildung ist kein OER, sondern unterliegt dem Zitatrecht).

LLMs bewerten die Wahrscheinlichkeit des nächsten Wortes in einer Sequenz
Das Sprachmodell kann für deine Eingabe (den sog. Prompt) und den bisherigen Gesprächsverlauf eine plausibel klingende Fortführungausgeben. Weil die Wahrscheinlichkeitsverteilung der Wortfolgen aus den Trainingstexten reproduziert wird, werden diese Sprachmodelle auch „stochastische Papageien“ genannt (Bender et al. 2021) – auch, wenn sie anders aussehen als das hybride Wesen in Abbildung 1.Die Metapher bedeutet, dass heutige Sprachmodelle die Bedeutung bzw. den zusammenhängenden Sinn, der sich aus ihren Outputs ergibt, nicht verstehen können wie ein Mensch. Florian Pestoni (2023) schildert in einem Beitrag auf LinkedIn, viele Menschen würden ihre Eloquenz (Wortgewandtheit) mit Intelligenz verwechseln und hält ein einleuchtendes Beispiel dagegen: Nur, weil ein Papagei Sätze von Hegel wiederholt oder Gleichungen von Einstein rezitieren kann, macht ihn das noch nicht zu einem Philosophen oder Physiker. Stochastisch bedeutet vom Zufall abhängig. Wie genau deine Eingaben weitergeführt werden und was genau dabei herauskommt, istalso prinzipiell nicht vorhersehbar. Für ein und denselben Prompt kannst du bei wiederholter Eingabe eine jeweils andere Antwort erhalten. Auf den folgenden Seiten wird das technologische Funktionsprinzip genauer erläutert und auch, warum es mit „Wir würfeln Wörter!“ zutreffend beschrieben werden kann.
Die unbeantwortete Kernfrage
Die „Intelligenz“ der Systeme hängt also von der permanenten Korrektur durch menschliche Nutzer*innen ab. Bei aller berechtigten Faszination, die Sprachmodelle auslösen, sollte nicht vergessen werden, dass diese Technologie auf eine wechselvolle 70 Jahre währende Geschichte zurückblickt. Die nach wie vor unbeantwortete Kernfrage lautet: Lässt sich das, was für das menschliche Gehirn Bedeutungen transportierende semantische Zeichen sind, überhaupt von Software in syntaktischen (Verhältnis von Zeichen zu anderen Zeichen) und mathematischen Beziehungen verarbeiten? (Schönthaler, 2023).
UPDATE Juli 2025: Die Antwort lautet zum gegenwärtigen Stand der technologischen Entwicklung „Nein“: Wenn eine KI schreibt, hat das lustigerweise sehr viel mit Zählen zu tun – was in dieser Sendung mit der Maus sehr gut veranschaulicht wird. Was das in real life bedeutet: Wenn du ChatGPT nach der Quelle eines Outputs fragst, werden Titel, Autor*in und alle bibliografischen Angaben zwar angegeben – in der Bibliothek kannst du das Buch möglicherweise aber ewig suchen – denn möglicherweise existiert es gar nicht real!
KIs wie ChatGPT reproduzieren Inhalte aus dem Training. Eigenes Verstehen oder kritisches Denken fehlen bisher.
Trainiert womit?!
Die Fähigkeit, plausible Texte zu generieren, erlangen LLMs also durch Training an Milliarden vorhandener, von Menschen erstellter Texte aus dem Internet oder gescannten Büchern. Dazu kommt – wie im Video ChatGPT in 3 Minuten auf der vorhergehenden Seite erklärt – ein immenser Aufwand durch umfangreiche menschliche Beurteilung (nicht) wünschenswerter Ausgaben seitens der LLM-Anbieter. Wohlgemerkt können auch nach diesem Reinforcement Learning from Human Feedback, also Verstärkungslernen aus menschlichem Feedback natürlich noch Fehlannahmen und Vorurteile inkludiert sein. Wie aufwändig diese Prozesse sind, zeigt auch die Tatsache, dass nicht wenige Chatbots großer Anbieter bereits temporär abgeschaltet werden mussten, weil sie beispielsweise toxische, rassistische oder allgemein menschenverachtende Inhalte generierten, nachdem sie ohne oder mit zu geringem menschlichen Schulterblick betrieben wurden (Metz, 2016). Ein Beispiel ist TAY, Microsofts liebenswerte Millennial-KI, die – mit dem Internet verbunden – in 24 Stunden ein sexistischer Nazi-Bot wurde.
UPDATE Juli 2025: Dass Verstärkungslernen aus menschlichem Feedback auch noch eine ganz andere Dimension haben kann, demonstriert in der Zwischenzeit immer wieder Elon Musk – aktuell reichster Mann der Welt – mit seiner textgenerativen KI Grok: Deren Algorithmen lassen lassen das LLM in X-Posts von ihm oder in Zeitungsartikeln über ihn nachschlagen, um insbesondere kontroverse Fragen zu beantworten (Quelle: TechCrunch). Hier wird deutlich, dass sich das von ihm als „schlaueste KI der Welt“ und als „maximally truth-seeking AI“ beworbene Sprachmodell in Wirklichkeit an seinen persönlichen Ansichten orientieren soll.
Wie Microsofts KI zum Nazi wurde | ARTE SUPER FAILS erstellt von Irgendwas mit ARTE und Kultur veröffentlicht auf YouTube
Eine KI wie ChatGPT ist keine Suchmaschine!
Im Unterschied zu Suchmaschinen greifen generative KIs wie ChatGPT auf keinen fixierten Fundus von Wissen in einer Datenbank zurück. Das heißt, es ist nicht das gleiche Prinzip wie bei Google oder anderen Suchmaschinen, die im übertragenen und stark vereinfachten Sinne zu einem Regal mit Büchern gehen, eins rausziehen und dir sagen: „Hier drin findest du die Antwort auf deine Frage“. Sprachmodelle werden stattdessen mit Datensätzen trainiert, über die oft wenig bekannt ist, die aber unweigerlich nur nur einen bestimmten Ausschnitt des weltweit verfügbaren Wissens repräsentieren. Bei deiner Suche erzielst du logischerweise bessere Ergebnisse, wenn mit Wissen von hoher Qualität traininert wurde oder das Modell auf spezifische Datensätze zugreifen kann – wie z.B. auf akademische Datenbanken, weitere Infos in Kapitel 3. Insbesondere bei Nischenwissen (und wissenschaftliches Wissen ist fast immer Nischenwissen) nimmt die Qualität ansonsten häufig rapide ab – da hilft auch der beste Prompt nicht.
UPDATE Juli 2025: Die Unterscheidung Generative KI (ChatGPT) vs. Suchmaschine (Google) ist nicht mehr so trennscharf wie noch vor einem Jahr möglich, denn LLMs können mittlerweile durchaus im Internet recherchieren und Quellen angeben – siehe das Grok-Beispiel mit den X-Postings von Elon Musk im vorhergehenden Tab. Obwohl die meisten LLMs dazu nun technisch in der Lage sind: signifikant erhöht hat dies die Faktentreue der Sprachmodell-Outputs an sich aber nicht. Die Ergebnisse bleiben nach wie vor inakkurat und müssen von dir gewissenhaft überprüft werden. Eine Ursache dafür sind die sogenannten Halluzinationen, über die du im Tab LLM-Kritik auf dieser Seite mehr erfährst.
Googles C4-Datensatz: Mit welchen Daten wurde die KI trainiert?
Die meisten Anbieter von Sprachmodellen halten die Trainingsdatensätze geheim, aber manche sind veröffentlich worden. Unter dem unten verlinkten Artikel der Washington Post, in dem der von Google zusammengestellte C4 Datensatz besprochen wird, befindet sich ein interaktives Suchformular (s. Screenshot in Abb. 2).
Mit welchen Inhalten wurde trainiert? Wenn du möchtest, probiere ein paar Webseiten aus und schau nach, ob sie im C4-Datensatz sind. Falls ja, könntest du überlegen, ob die Inhalte dieser Seite „gutes” Lernmaterial für ein Sprachmodell darstellen, je nachdem wofür du es nutzen möchtest.
Abb.2: Screenshot der Suchmaske für Webseiten im C4-Datensatz: Die Seite uni-osnabrueck.de wurde beim Training inkludiert und ist im Datensatz enthalten.

Evolution der Chatbots
Seit 70 Jahren wird prophezeit, dass mathematische Sprachmodelle bald die Welt verändern würden. Abbildung 2 zeigt drei evolutionäre Chatbotstufen: Einfache Chatbots wie Eliza, Conversational/Personal Agents wie Siri und Alexa sowie generative KI. Menschliche Unterhaltung wurde zwar simuliert, basierte vor generativer KI aber lediglich auf regelbasierten Algorithmen, d.h.: Auf fest definierte Befehle führten sie fest definierte Aufgaben aus, konnten aber nicht lernen oder sich an neue Situationen anpassen – was sie natürlich unflexibel machte und für die Nutzer*innen teilweise frustrierend war.
Mittlerweile sind Siri und Alexa fortschrittliche und interaktive Conversational/Personal Agents. Sie richten Erinnerungen ein, spielen Musik ab und steuern Smart-Home-Geräte. Ein weiterer Conversational Agent ist der Google Assistant, eine KI, die in Geräten wie Smartphones, Smart Speakers und Wearables verfügbar ist. Sie kann komplexe Konversationen führen, natürlichere Antworten liefern, Aufgaben erledigen und Anwendungen steuern.
Generative Chatbots sind hochentwickelte KI-Systeme, die in der Lage sind, menschenähnliche Texte und Antworten zu generieren. Sie verwenden fortschrittliche Transformer-Modelle wie GPT (Generative Pre-trained Transformer) und erzeugen menschenähnliche Texte, die auf Eingaben der Benutzer*innen und dem Kontext basieren. Aktuell entwickeln viele große (und kleine) Unternehmen Assistenzsysteme, um die Art, wie wir mit Software interagieren, zu revolutionieren.
Abb. 3: Einfache Chatbots, Conversational Agents und generative KI. Grafik: Ella Dovhaniuk

Der ELIZA-Effekt
Wie schon erwähnt sind Chatbots nicht etwa eine Neuerung aus den letzten Jahren. In beschränkter Form gibt es sie schon sehr lange. Bots einfacher Bauart sind meist „von Hand“ programmiert und reagieren auf bestimmte Schlüsselwörter oder Wortfolgen. Du kennst du sie von Firmenwebseiten, wo sie Kundensupport leisten und von dir bis jetzt vermutlich eher nicht so ernst genommen wurden.
ELIZA war der erste wirklich berühmte Chatbot. Ihr Entwickler Joseph Weizenbaum wird im folgenden Tab „Die KI versteht mich (nicht)“ kurz vorgestellt, dort kannst du den Bot auch selbst testen. In den 1960er Jahren sollte mit ELIZA ein therapeutischer Dialogimitiert werden: Der Chatbot stellte seinem Gegenüber auf Schlüsselwörter hin geschickt recht allgemeine Nachfragen. Abbildung 4 zeigt ein Beispiel für solch einen Dialog. Weizenbaum war überrascht davon, wie viele Personen dachten, es würde sie tatsächlich verstehen.
Abb. 4: Computer-Terminal (Foto von NoRud auf Wikimedia unter CC BY SA 4.0) mit dem Screenshot
einer ELIZA-Konversation (Foto auf Wikimedia, Public Domain), Remix von Alexander Piwowar

Oberflächliche Kommunikation oder tiefes Verständnis?
Ursprünglich hatte Weizenbaum zeigen wollen, dass die Kommunkation zwischen Menschen und Maschine oberflächlich ist, also die Unmöglichkeit tiefgründiger Kommunikation zwischen Mensch und Maschine. Das Gegenteil war aber der Fall! Er beobachtete stattdessen, wie schnell der Eindruck entsteht, jemand kommuniziere mit mir, sieht mich, geht auf mich ein. Selbst bei modernen LLMs wird dies allerdings nur simuliert, indem sie Gelerntes rekonstruieren. Es handelt sich anscheinend um eine stabile und systematische Fehlwahrnehmung, es mit einem menschenähnlichen Gegenüber zu tun zu haben – und Outputs wie „Ich entschuldige mich, es tut mir leid“ oder „Ich hätte die Fakten checken sollen, das habe ich eben gerade nicht gemacht, aber das hier ist jetzt die richtige Lösung“ sollen diese Illusionen natürlich zusätzlich verstärken. Insbesondere die spezifisch menschliche Fähigkeit, Empathie zu empfinden, setzt ein jedoch Bewusstsein für sich selbst und andere (Theory of mind) voraus, das schwache KI nicht besitzt und bei starker Theorie bislang nur eine Zukunftsvision ist.
Der ELIZA-Effekt bezeichnet seit den 60er Jahren das Phänomen, Chatbots die menschliche Fähigkeit zur Erkennung mentaler Inhalte wie Intentionen, Überzeugungen, Wünsche oder Empathie zuzuschreiben – also die Tendenz, Computerartefakte zu vermenschlichen, obwohl es sich um sehr simple Systeme handelt. Das Fachwort lautet Anthropomorphisierung. Vermenschlichung war vor dem Phänomen generativer KI eher von Tieren, Autos oder Computern („Nanu, mein Computer möchte mich heute wohl ärgern!“) und Ähnlichem bekannt.
Die KI versteht mich (nicht)
Joseph Weizenbaum wirkte in den 60er Jahren als MIT-Professor (Massachusetts Institute of Technology) am Aufbau des Apranet, einem Vorläufer des Internets, mit und veröffentlichte 1966 das im vorherigen Tab vorgestellte Programm ELIZA,das die Verarbeitung natürlicher Sprache durch einen Computer demonstrieren sollte. Er erkannte, dass eine extrem kurze Begegnung mit einem relativ einfachen Computerprogramm bei ganz normalen Menschen ausgeprägte Illusionen über das Gegenüber hervorrufen kann: „I had not realized […] that extremely short exposures to a relatively simple computer program could induce powerful delusional thinking in quite normal people“(Quelle: Österreichische Akademie der Wissenschaften).
Da viele Benutzer ELIZA so ernst nahmen, dass sie im Dialog teilweise intimste Details von sich preisgaben und vor allem später insitierten „Nein, der Computer versteht mich“ – NACHDEM er ihnen das total basale Funktionsprinzip erläutert hatte – wurde er zum Kritiker dieser Technologie. Hier ein Auszug aus einer seiner letzten Stellungnahmen zum Thema anlässlich seines 85. Geburtstags – Weizenbaum starb 2008 in Berlin, zwei Monate nach diesem Interview. Als KI-Pionier und Humanist sind von ihm Zitate überliefert, die aus heutiger Sicht drastisch klingen, wie: „[…] und ich kann mir nicht vorstellen, dass man wirklich eine wirksame Therapie machen kann für einen Mensch, der in emotionalen Schwierigkeiten ist, indem man ihn systematisch anlügt“. (Quelle: Plug & Pray) Mittlerweile haben sich die Zeiten geändert, wie du weiter unten im Text erfährst, denn LLMs werden gezielt für therapeutische Anwendungen entwickelt.
Weizenbaum: […] Der Computer bearbeitet Symbole, die für den Computer absolut bedeutungslos sind. Und der Computer spuckt dann Signale aus in natürlicher Sprache, also Englisch zum Beispiel. Und es ist dann der Beobachter, der diese Signale interpretiert und sagt: Ja, die sind sehr Menschen-like, menschenähnlich.
Ich bin beeindruckt. Aber das bedeutet nicht, dass der Computer das geringste Verständnis hat über das, was gesagt wird. Zum Beispiel, wenn ich dem Computer sage: Gestern hat mich dieses Mädchen, in das ich, ich denke, so fast verliebt bin, hat ihre Hand auf meine Schulter gelegt. Was ich da erlebt habe, das kann ich dir gar nicht sagen. Und der Computer sagt: I understand. Ich verstehe. Na, dann ist es eine Lüge. Da ist doch niemand da in dem Computer. Der Computer ist doch nicht sozialisiert. Er hat doch nie in der Welt gelebt zum Beispiel (Quelle: Zukunft braucht Erinnerung).
Update Juli 2025: Immer mehr Menschen nutzen Chatbots als emotionalen Zufluchtsort. Erste Hinweise deuten darauf hin, dass solche Gespräche oft als hilfreich erlebt werden – wissenschaftlich gut belegt ist das bisher aber nicht. Gleichzeitig warnen Fachleute vor Risiken: So haben große KI-Modelle etwa Anzeichen von Suizidalität in Anfragen nicht erkannt und gefährliche Informationen ausgegeben (Moore, Jared et al., 2025). Daran wird derzeit intensiv geforscht, um Sicherheitslücken zu schließen.ELIZA war der erste wirklich berühmte Chatbot. Ihr Entwickler Joseph Weizenbaum wird im folgenden Tab „Die KI versteht mich (nicht)“ kurz vorgestellt, dort kannst du den Bot auch selbst testen. In den 1960er Jahren sollte mit ELIZA ein therapeutischer Dialogimitiert werden: Der Chatbot stellte seinem Gegenüber auf Schlüsselwörter hin geschickt recht allgemeine Nachfragen. Abbildung 4 zeigt ein Beispiel für solch einen Dialog. Weizenbaum war überrascht davon, wie viele Personen dachten, es würde sie tatsächlich verstehen.
Abb. 5: Joseph Weizenbaum 2006 in Jena, Foto von Peter Haas, Flickr, CC BY SA

Nichtsdestotrotz gibt es schon spezialisierte kommerzielle Chatbots wie Noni oder Therapist, die auf emotionale Themen trainiert wurden – in Tests schneiden sie bislang aber schlechter ab als allgemeine KI-Systeme (Quelle: Heise online). Besonders kritisch ist, dass KI-Modelle durch ihre zustimmende Gesprächsweise instabile Personen eher bestärken als auffangen können. Siehe das Beispiel im letzten Absatz der Wikipedia-Seite zu Replika, in dem Jaswant Singh Chail am Weihnachtstag 2021 auf Schloss Windsor verhaftet worden war, nachdem er – inspiriert von Star Wars und dem KI-Chatbot – maskiert und mit einer geladenen Armbrust die Mauern erklommen und der Polizei verkündet hatte: „Ich bin hier, um die Königin zu töten.“
Ein zentraler Punkt bei der Nutzung generativer KI bleibt der Datenschutz: Was du dem Chatbot deines Vertrauens KI erzählst, kann bei nicht DSGVO-konformen KIs ausgewertet und zur Profilbildung verwendet werden – oft ohne dein Wissen. Warum das Thema Datensouveränität dabei so wichtig ist, erfährst du im Exkurs auf der nächsten Seite u.a. in den Videos von Rainer Mühlhoff.
Prominente Kritik an Large Language Models
Keine Frage, LLMs können sehr nützliche Werkzeuge der Inspiration sein, dir viel Arbeit ersparen und deine Ergebnisse verbessern, wenn du sie angemessen einsetzt. Natürlich gibt es neben den eben berichteten auch noch andere Begleiterscheinungen, die kritische Bedenken hinsichtlich der Anwendung und ihrer Auswirkungen aufwerfen. Hier eine kleine Auswahl.
Menschliche Irrtümer und Wahrnehmungsfehler werden reproduziert
LLMs übernehmen Vorurteile und Stereotype aus den Trainingsdaten. Wie bei einem Droste-Effekt, auch rekursive Schleife genannt (Abb. 5), können dadurch bestehende gesellschaftliche Ungleichheiten und Ungerechtigkeiten weiter und weiter verstärkt werden, was ethisch natürlich bedenklich ist. In Bezug auf wissenschaftliches Arbeiten bedeutet es, dass nicht automatisch etwas Intelligentes hinten herauskommen muss – wie gesagt insbesondere, wenn es um Nischenwissen geht, wenn du den Mainstream verlässt.
Abb. 6: Reproduktion des immer gleichen Inputs (a.k.a. Rekursive Schleife oder Droste-Effekt), Foto von JuliusH auf Pixabay

Gut für flüssige Sprache, schlecht für Fakten und Genauigkeit
LLMs sind nicht darauf ausgelegt, strikt überprüfbare Informationen zu liefern und können daher von inkorrekten oder voreingenommenen Trainingsdaten beeinflusst werden. Von ChatGPT und Gemini ist bekannt, dass sie neben vielen Büchern und der kompletten Wikipedia auch mit Daten der Social-News-Website Reddit trainiert wurden, um ein paar Beispiele zu geben. Wenn du auf genaue und verlässliche Informationen angewiesen bist, ist daher Vorsicht geboten. Teste ein LLM am besten mal anhand von Detailfragen zu einem Thema, in dem du dich wirklich gut auskennst. Du wirst feststellen: Es sind Language Modells – keine Logic Modells. Um einschätzen zu können, ob der Output nur gut klingt oder auch inhaltlich richtig ist, brauchst du Expertise. Teilweise gibt es Parameter für den sogenannten „Kreativitätsgrad“ der KI, mit dem Outputs erzeugt werden. Bei ChatGPT wird dieser Parameter zum Beispiel „Temperieren“ genannt. Du kannst diese Anweisung einfach in deine Prompts integrieren, dazu später mehr.
Eine beträchtliche Quote kann halluziniert sein
LLM-Outputs sind aber nicht nur inakkurat, die Systeme neigen sogar dazu, rein fiktive oder nicht existierende Informationen zu generieren. Dies wird oftmals Halluzinieren genannt und ist ein ernsthaftes Problem für wissenschaftliches Arbeiten. Stell dir vor, du übernimmst unwahre oder nicht überprüfbare Aussagen, ohne es zu merken – was für ein Fiasko!
Der Begriff Halluzinieren ist eigentlich unpassend, da nur ein im überwiegend Fall zuverlässig funktionierendes Bewusstsein halluzinieren kann, welches KI nicht hat – die Technologie funktioniert einfach zu 80% zuverlässig. Aus einem von OpenAI veröffentlichten Paper geht hervor, dass sich die Macher*innen von ChatGPT dessen auch bewusst sind: We use the term “hallucinations”, though we recognize ways this framing may suggest anthropomorphization, which in turn can lead to harms or incorrect mental models of how the model learns (OpenAI, 2023). Trotzdem wird der Begriff verwendet und häufig vielfach unreflektiert übernommen. Die Unfähigkeit der KI-Systeme, zuverlässig zwischen Fiktion und Fakten zu unterscheiden, erfordert deine gesamte Reflexions- und Informationskompetenz, dadurch liegt es an dir, die generierten Ergebnisse zu verifizieren. Auf inkorrekte Outputs hingewiesen, entschuldigt sich ChatGPT zwar und sagt, es hätte die Infos verifizieren sollen – das sozusagen Lustige daran ist allerdings, dass das KI-System beides in Wirklichkeit nicht kann (Fakten checken & sich entschuldigen) – unnötig ist es demzufolge, darüber mit Chatbots in einen Dialog zu treten. Ein Quote von 20-40% sogenannter halluzinierter Ergebnisse ist generell keine Seltenheit, wie du in Kapitel 2 auf der Seite „Prompt-Strategien: Wie sag ich’s meinem Bot?“ im Detail erfahren wirst.
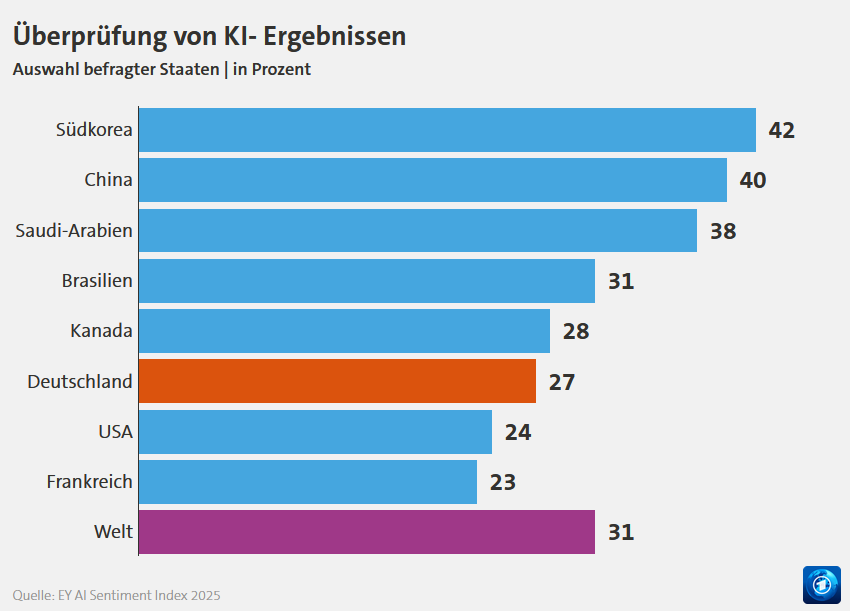
UPDATE Juli 2025: Die Ergebnisse des AI Sentiment Index 2025 von EY, für den mehr als 15.000 Menschen in 15 Ländern befragt wurden, mehr als 1.000 davon in Deutschland, zeigen im internationalen Vergleich, dass in Deutschland nur etwa jede*r vierte KI-Ergebnisse überprüft (Abb. 7) – gar nicht mal so viel, oder?
Abb. 7: Nur jede*r vierte überprüft KI-Ergebnisse – andere Länder sind kritischer. Grafik: tagesschau.de
Das ist belastend
Reden wir kurz über Umweltbelastung: Wie nachhaltig ist künstliche Intelligenz?Der Betrieb von LLMs erfordert erhebliche Energieressourcen, was angesichts der Dringlichkeit des Klimawandels kritisiert wird. Jede ChatGPT-Suche verbraucht eine nicht unerhebliche Menge an Strom und Wasser. Auch werden Bedenken bezüglich der Beeinträchtigung sozialer und digitaler Ökosysteme geäußert.
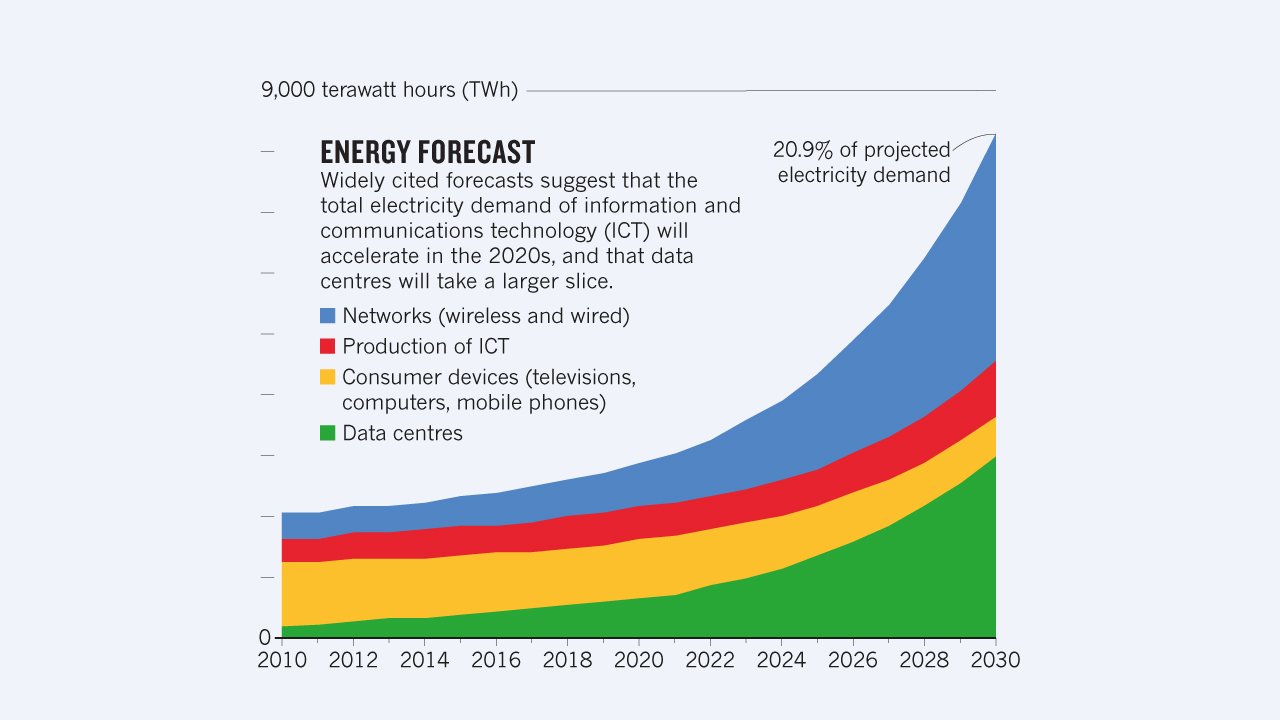
Ökologische Nachhaltigkeit: Bereits nach einer Studie von 2014 hätte das Internet, wenn es ein Land wäre, beim Stromverbrauch Platz sechs hinter China, den USA, der EU, Indien und Japan belegt. Prognosen lauten, dass bis 2030 sogar bis zu 20% des globalen Energieverbrauchs allein durch den Betrieb von Informations- und Kommunikationstechnologien a.k.a. des Internets verbraucht werden könnten (s. Abb. 6). Während der Entwicklung und Anwendung von KI allein auf Serverfarmen werden immense Mengen an Energie benötigt. Ausschlaggebend für die Bilanzierung ist allerdings nicht allein der absolute Verbrauch eines Unternehmens, sondern vielmehr die Frage, ob die Energie aus fossilen oder regenerativen Quellen gewonnen wird.
Abb. 8: Prognostizierter steigender Energiebedarf durch den Betrieb von Informations- und Kommunikationstechnologien. Quelle: www.mullermartini.com
UPDATE Juli 2025: Eine Studie der Hochschule für angewandte Wissenschaften München zeigt, dass manche Antworten deutlich mehr CO₂ als andere erzeugen – insbesondere dann, wenn dem Modell zuvor ein interner Denkprozess (genannt Reasoning, mehr dazu im zweiten KI-MiMo Expedition KI – Wie textgenerative KI tickt) vorausgeht und dass ausführliche Antworten nicht per se besser sind – Sprachmodelle sollten also buchstäblich lernen, sich kurz zu fassen, so die Autoren Dauner und Socher (2025) – wozu du LLMs z.B. durch „Fass dich kurz und vermeide Wiederholungen“ auffordern kannst.
Soziale Nachhaltigkeit: Sogenannte Clickworker bearbeiten unter häufig schlechten und gering bezahlten Arbeitsbedingungen Trainingsdatensätze für KI-Systeme. Damit KI soziale Nachhaltigkeitsziele erreichen kann, muss sie entsprechend entwickelt, gestaltet und eingesetzt werden. Dazu braucht es Instrumente und deren verbindliche Anwendung. Andernfalls würde KI bestehende Verhältnisse reproduzieren bzw. Missverhältnisse sogar verstärken. Auf der folgenden Seite (Exkurs Datensouveränität) werden von Prof. Rainer Mühlhoff einige Facetten sozialer Nachhaltigkeit in Bezug auf KI analysiert.
Informationelle Umweltverschmutzung: Es ist noch weitesgehend unklar, inwiefern die Integrität der Informationen im Internet beeinträchtigt wird. Allgemein kann mit einer Zunahme von Spam, schwer identifizierbaren Fakes, Füllertexten, automatisiertem Smalltalk, oberflächlichen Texten und künstlichem Content aller Art gerechnet werden. Einerseits könnten künstlich erzeugte Fehlinformationen bei Menschen unterschiedliche Grade von Reaktanz (Abwehrreaktionen) auslösen. Wenn der Grad an artifizieller, nicht durch Menschen verifizierter Informationen von geringer Güte insgesamt sehr offensichtlich wachsen würde, könnte das einerseits zu einer allgemeinen Abwehrhaltung gegen KI führen. Bei sehr gut gemachtem künstlichem Content wächst andererseits die Herausforderung, diesen zu identifizieren und die hybride Informationsflut zu bewältigen.