
Der Begriff Datensouveränität wird in unterschiedlichen Kontexten ohne eine feststehende, allseits akzeptierte Definition verwendet. Auf dich als Individuum bezogen ist gemeint, dass du die Kontrolle über dich betreffende Daten und ihre Erhebung, Speicherung und Verarbeitung behältst. Die Bezeichnung „gläsern“ zu werden, also durchleuchtet werden zu können, stammt übrigens aus einer Zeit lange vor der Entwicklung des Internets in seiner heutigen Form.
Hintergrund: Viele Menschen geben online teilweise freiwillig sehr viele Daten über sich preis, die dann aber eher unfreiwillig ausgewertet werden, siehe Abbildung 1. Unternehmen wie Meta – das jedes Mal einen Tracking Code einsetzt, wenn du beispielsweise über den In-App-Browser von Instagram eine Website besuchst – erstellen daraus Sozialprofile, Persönlichkeitsprofile und Bewegungsprofile, was ihnen die Bezeichnung „Datenkraken“ eingebracht hat.
Die Abbildung stammt aus einem sehr lesenswerten Artikel über digitale Identität, den Katarzyna Szymielewicz geschrieben hat. Sie unterscheidet darin drei Schichten. Nur eine davon kannst du ansatzweise kontrollieren, und zwar das, was du teilst. Es sind die Likes, Kommentare und Postings, die hochgeladenen Fotos sowie Suchanfragen oder Webseiten, die du besucht hast und auf denen du getrackt wirst. Prof. Rainer Mühlhoff berichtet im Video „Was darf KI?“ (s.u.), dass auch Rückschlüsse über dich abgeleitet werden können, wenn andere, mit denen du in Verbindung stehst, freigiebig mit ihren Daten sind.
Die Datenschutzgrundverordnung (DSGVO) ist Katarzyna Szymielewicz zufolge ein wichtiger Schritt in Richtung digitale Souveränität, weil Unternehmen, die unsere Daten sammeln und profilieren, diese auf Anforderung transparent machen müssen.
Abb. 1: Marcin Antas & Kamil Śliwowski / Panoptykon Foundation.

Datensouveränität heißt: Du entscheidest, was mit deinen Daten passiert. Sie gehören dir – und dürfen nicht einfach zweckentfremdet werden. Du könntest sonst in Schubladen landen, die dir gar nicht passen.
Mehr Datensouveränität auf deiner Safari
In diesem Tab geht es nicht um KI-Tools, sondern um ein paar konkrete Tipps, wie du dich ganz allgemein vor ungewollten Ausspähungen im Internet schützen kannst, wenn du willst. Natürlich kommt es zunächst darauf an, welche Apps du überhaupt benutzt. Oft lassen sich Apps oder Produkte ohne die Angabe persönlicher Daten wie Name, Geburtstag oder Telefonnummer gar nicht in Betrieb nehmen. Oder man erlaubt bereitwillig, Daten zu speichern, weil dies den Bedienkomfort erhöht, z.B. um sich nicht immer wieder neu einloggen zu müssen oder sich leicht mit anderen Geräten oder Menschen verbinden zu können.
Bei der Anmeldung in einem Sozialen Netzwerk werden beispielsweise häufig bereitwillig die gesamten Kontakte übertragen. Später kann dies jedoch unter Umständen nicht mehr gelöscht werden. Wie bei Dr. Datenschutz nachgelesen werden kann, kann es vom Betreiber des Netzwerks, beispielsweise im Rahmen von Werbeverträgen, weitergegeben werden.
Digitaler Fussabdruck: Finde heraus, was Google über dich weiß
Dieser Ratgeber des t3N-Magazins ist potenziell interessant für alle Nutzer*innen von Google-Diensten, denn anhand der Links zu einigen Protokollen können die eigenen Spuren leicht sichtbar gemacht werden. Wie sieht Google mich, was sagt mein Standortverlauf über mich aus und nach welchen Begriffen habe ich gesucht?
Sei nicht naiv!
Das Geschäftsmodell sogenannter „Schutzdienste“ besteht darin, dir zu versprechen, dass sie deine persönlichen Einträge bei Datenbrokern für dich löschen. Da es immens viele Datensammler gibt, ist höchst fraglich, ob dieses Versprechen wirklich eingelöst werden kann, Details dazu in diesem Heise-Artikel. Wenn du aus qualifizierter Quelle wissen willst, wie du dich persönlich identifizierbar machende Informationen besser unter Kontrolle behältst, ist der kostenlose Kurs am Ende dieses Tabs möglicherweise interessant für dich.
Abb. 2: Datenbroker schlagen Kapitel aus persönlichen Informationen: „Sie kennen uns nicht, aber wir kennen Sie.“ Generiert von Alexander Piwowar mit Midjourney

Was du konkret tun kannst
Am besten nutzt du einen sicheren Internetbrowser, der Tracking blockiert. Chrome zum Beispiel gehört zu Google, wo viel Geld mit Werbung verdient wird und ist diesbezüglich kein gutes Beispiel. Aber auch der Firefox-Browser von Mozilla trackt, wenn man ihn lässt. Auf Zeit Online erfährst du, wie du ihn ganz leicht in einen datenschutzfreundlichen Browser umwandeln kannst. Im Gegensatz zu Google Chrome oder Microsoft Edge ist das hier jederzeit möglich. Wenn dir digitale Selbstbestimmung wichtig ist, nutze und konfiguriere – als Gegenbeispiel – bei Firefox die Browsereinstellungen für weniger Tracking, leere regelmäßig den Cache und lösche die Cookies. Firefox ruft übrigens Goole-Ergebnisse ab, ebenso wie Startpage.com. Startpage anonymisiert deine Eingaben automatisch, bezeichnet sich als „die sicherste Suchmaschine der Welt“ , ist eine niederländische Alternative und kann in Firefox integriert werden.
Bei HeyData erfährst du übrigens, wie Meta die Vermarktung personenbezogener Daten im Vergleich mit anderen Apps wie TikTok perfektioniert hat. Die durchschnittlichen Daten einer Person, die es in einem Jahr sammelt, werden für dort geschätzte 200 Euro vermarktet. Wer seinen Instagram-Account oder andere Apps bei Meta nicht löschen will, kann bei Interesse immerhin seine Datenschutz-Einstellungen verbessern. Das ist in den Privatsphäre-Einstellungen möglich. Es gibt auch gute Anleitungen zu den Einstellungen für Werbung.
Die Problematik von KI-Tools konkret
Je nachdem, wie großzügig du mit deinen Daten um dich wirfst, kann deine Privatspäre unter Umständen nicht vor unbefugtem – im Sinne von nicht durch dich selbst bestimmtem – Zugriff geschützt sein. Und es geschieht nicht oft, dass der Dschungel das, was er einmal verschlungen hat, wieder ausspuckt.
Wenn mehrere Datensätze über dich miteinander verbunden werden, kann das Schlüsse über dich ableiten lassen, von denen du vielleicht selber gar nicht weißt. Vor allem, wenn du Spuren auf mehreren Plattformen hinterlässt, die zu ein und demselben Konzern, insbesondere den sogenannten Big Tech gehören – Google, Amazon, Meta, Apple und Microsoft –dann weiß dieser Konzern jetzt schon eine ganze Menge über dich, wenn mensch beispielsweise an das Thema Kreditvergabe oder Job-Bewerbung denkt. Auch gibt es Datenbroker, bei denen persönliche Datensätze ganz legal gekauft werden können, z.B. für Direktmarketing.
Digitale Selbstbestimmung bedeutet, die Abhängigkeit von großen Technologieunternehmen zu verringern und sicherzustellen, dass Daten nicht fremdbestimmt für intransparente Zwecke, sondern im Interesse der Nutzer*innen verwendet werden, eben selbstbestimmt, souverän. In Bezug auf Sprachmodelle könntest du beispielsweise auf Anbieter setzen, die deine Herkunft verschleiern, so wie Chatbots von Hochschulen, die dies für dich übernehmen, siehe kiwian der Universität Osnabrück. Dadurch kannst du das Bild bzw. Profil, das sich durch deine persönlichen Daten ergibt, begrenzen (Abb. 3). Du kannst dir das technische Prinzip in etwa wie eine VPN (Virtual Private Network) vorstellen, also eine sichere, verschlüsselte Verbindung über ein öffentliches Netzwerk.
LLMs schmeicheln, weil zu ehrliche Nutzerprofile Abwehr auslösen
Auf der vorhergehenden Seite wurden bereits für den therapeutischen Dialog trainierte Sprachmodelle vorgestellt, inklusive der potenziellen Gefahren für labile Personen durch die Tendenz der LLMs, Menschen in ihren Wahrnehmungen zu bestätigen. Der X-Post von Ex-Microsoft-Manager Mikhail Parakhin (Abb. 4) zeigt, dass die dadurch häufig extrem schmeichlerische (engl.: sycophant) Art von KI-Chatbots nach Beschwerden über zu ehrliche Persönlichkeitsanalysen bewusst eingeführt wurde: Das eigene Profil einsehen zu können, hatte bei Nutzer*innen starke Abwehrreaktionen ausgelöst.
Wie auf der vorhergehen Seite bereits erläutert, steht RLHF für Reinforcement Learning from Human Feedback (Verstärkungslernen aus menschlichem Feedback). Es ist eine Technik im Bereich des maschinellen Lernens, bei der menschliches Feedback genutzt wird, um KI-Modelle zu optimieren.
Abb. 3: Digitale Selbstbestimmung: Welche Rückschlüsse über dich dürfen aus deinen persönlichen Daten gezogen werden? Generiert von Alexander Piwowar mit Leonardo.ai

Abb. 4: Der X-Post von Ex-Microsoft-Manager Mikhail Parakhin zeigt die Abwehr von Nutzenden beim Einsehen der über sie angelegten Profile

Eine sichere Lösung: kiwi, dein KI-Chat an der Uni Osnabrück
Die Uni Osnabrück bietet ihren Mitgliedern mit kiwi einen datenschutzkonformen Zugang zu den Sprachmodellen von OpenAI, die auch hinter ChatGPT stehen, zur Verfügung – so kannst du ChatGPT und weitere Sprachmodelle sicher nutzen, denn:
- Um über kiwi mit den GPT-Sprachmodellen interagieren, brauchst du dir keinen eigenen Account bei OpenAI anlegen. Für den kiwi-Login benötigst du lediglich deine LDAP-Kennung, mit der du dich bspw. auch bei Stud.IP einloggst.
- kiwi übermittelt bei der Anmeldung keine persönlichen Daten an OpenAI und verhindert, dass Eingaben (“Prompts”) einer Person zugeordnet werden können.
- Wenn du das normale ChatGPT nutzt, verwendet OpenAI deine Eingaben zum Training seiner Sprachmodelle. Alle Anfragen, die du über kiwi stellst, darf OpenAI dagegen nicht zum Training seiner Modelle nutzen!
Wenn du mehr über kiwi wissen willst: Im zweiten KI-Mikromodul Expedition KI – Wie textgenerative KI tickt gibt es eine ganze Seite zu deinem Chatbot an der Uni Osnabrück, mit dem du außer ChatGPT auch noch Modelle anderer Hersteller nutzen kannst, ohne dass diese Profile über dich bilden können.
AI Act der EU
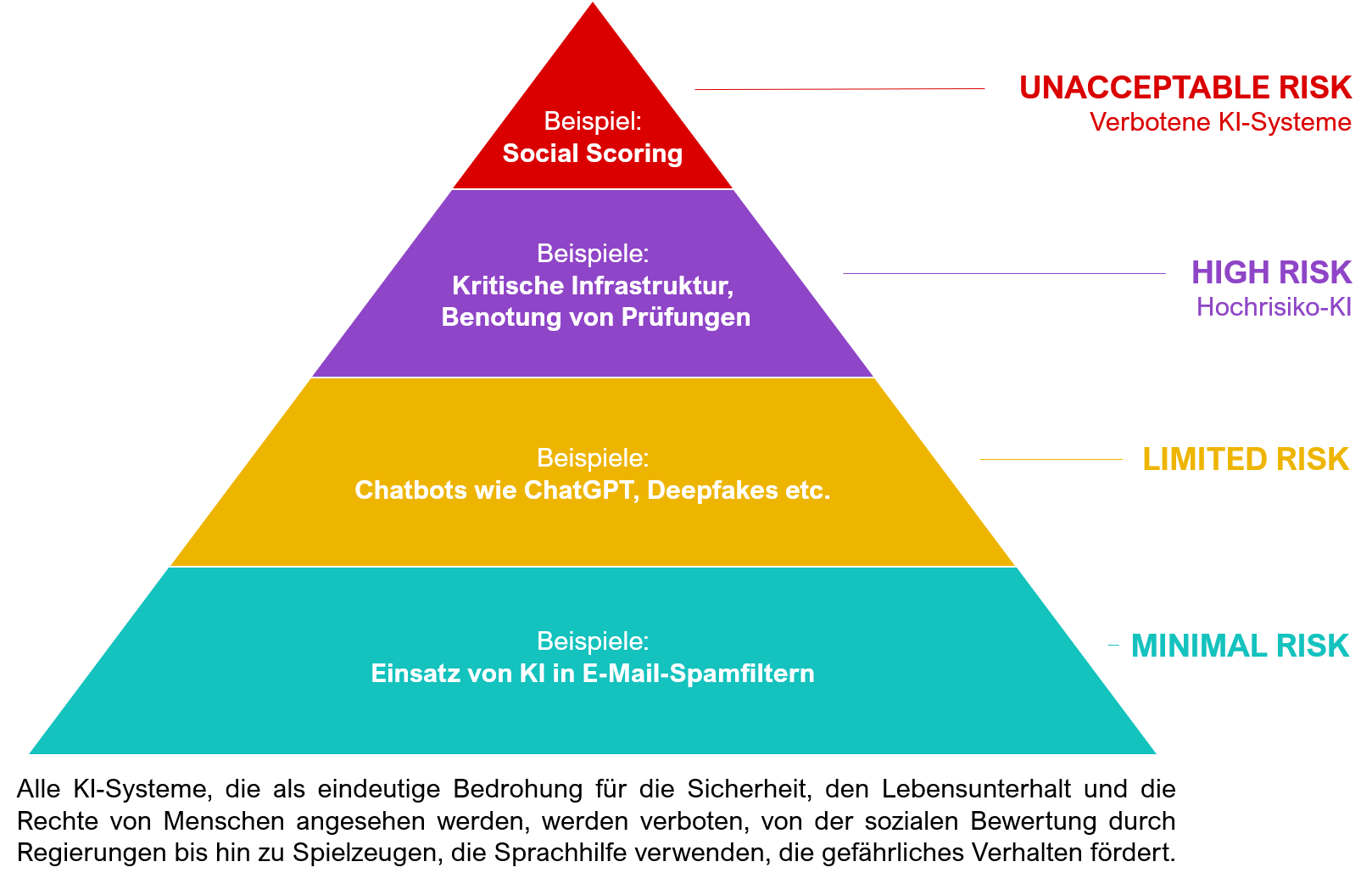
Der Artificial Intelligence Act der Europäschen Union erfasst verschiedene Gefahren, die mit KI-Anwendungen verbunden sind. Der Regulierungsrahmen definiert vier Risikostufen, siehe Abbildung 4. Oft ist gar nicht sofort nachvollziehbar, worin denn überhaupt das Risiko in Bezug auf den Schutz deiner Daten im Internet besteht. Social Scoring Systeme wie in China lassen schnell erahnen, wie KIs beispielsweise zur Beeinflussung und Überwachung von Menschen eingesetzt werden können.
Im deutschen Datenschutzrecht hingegen ergibt sich aus dem sogenannten Grundsatz der Erforderlichkeit das Gebot der Datenminimierung, welches sich in § 3a Bundesdatenschutzgesetz (BDSG) wiederfindet. Dies bedeutet: Prinzipiell sind so wenig personenbezogene Daten zu erheben, zu verarbeiten und zu nutzen, wie nur möglich.
Daraus folgt, dass Datenverarbeitungsprozesse so einzustellen sind, dass sie mit möglichst wenigen Daten auskommen. Vorzuziehen sind insbesondere Datenverarbeitungsprozesse mit Anonymisierung und Pseudonymisierung. Gibt es einen Weg, weniger persönliche Daten zu erheben, um anfallende Prozesse zu ermöglichen, muss dieser gewählt werden.
Abb. 5: Die vier Risikostufen im AI-Act der EU, Darstellung nach Andrea Schlotfeld, HND BW unter CC BY 4.0 und dem Original auf der Webseite der EU-Kommision, Remix von Alexander Piwowar
Was du bzgl. Datensouveränität individuell tun kannst: ChatGPT & Co. deine Daten nicht verraten!
Im Umgang mit ChatGPT raten Experten davon ab, zu viel persönliche Informationen zu offenbaren und geben zwei zentrale Empfehlungen:
- Gib nur wenige persönliche Daten preis, u.a. weder private Accounts und E-Mail-Adressen noch dein korrektes Geburtsdatum. Als Name kann ein Pseudonym hinterlegt werden.
- Vertrauliche Informationen sollten nicht über ChatGPT geteilt werden.
Was darf Künstliche Intelligenz?
Prof. Rainer Mühlhoff leitet den Forschungsbereich Ethik und kritische Theorien der Künstlichen Intelligenz am Institut für Kognitionswissenschaft der Universität Osnabrück. In diesem Video führt er aus, wie die Science Fiction Vorstellung von KI von der aktuellen sozialen Realität ablenkt und dass die sozial relevanten Fragen nach KI erst einmal identifiziert werden müssen. KIs sind zum allergrößten Teil keine materiell greifbare Entität (kein greifbarer Gegenstand), wie die 10.000 Bilder von humanoiden Robotern nahelegen, die überall zu sehen sind – dabei handele es sich um ein weitverbreitete Fehleinschätzung des Phänomens KI.
Der Großteil KI findet im Kontext vernetzter Medien statt, also im Internet – nicht als Roboter, Autos oder Drohnen. Es ist insofern irreführend, KIs als menschenähnliche Entitäten zu betrachten, denn: Vorhersage-KIs sind viel verbreiteter. Sie werden gezielt dafür hergestellt, Menschen subtil unterschiedlich zu behandeln.
Was darf Künstliche Intelligenz? Eine Frage der Ethik? erstellt von „Osnabrücker Wissensforum“ der Universität Osnabrück veröffentlicht auf YouTube
Rainer Mühlhoff auf dem Chaos Communication Congress in Hamburg: “KI – Macht – Ungleichheit”
Ein weiteres populäres Bild von KI, das in den Medien vermittelt wird, sieht so aus, dass das Gehirn durch digitale computionale Prozesse simuliert wird. Im diesem Vortrag führt Prof. Rainer Mühlhoff aus, warum dieses Bild falsch ist. Stattdessen geht es ihmzufolge vielmehr um das intelligente Design von Feedbackschleifen. Mit der Veröffentlichung hört das Training (siehe vorherige Seiten) eben nicht auf, sondern die KI wird durch die Nutzer*innen immer weiter trainiert. Insofern können die KIs als soziotechnisches, d.h. kybernetisches Mensch-Maschine-System betrachtet werden.
Dieses tatsächliche Bild steht laut Prof. Rainer Mühlhoff zu den Nachhaltigkeitszielen der UN in einem inhärenten Konflikt, wenn KI nicht besser reguliert wird. Die Feedback-Loops, gar nicht das Programieren von Code selbst, ermöglicht das umfangreiche Auslesen menschlicher kognitiver Leistungen an den digitalen Interfaces, die wir täglich nutzen. Als Beispiel für das Design von Feedbackschleifen greift er auf die Geschichte des Facetaggings auf Facebook zurück. Bei Minute 10:00 erfährst du auch, was die für Facebook wirklich interessante Infomation ist, wenn sie fragen, ob sie ein Foto von dir nutzen dürfen oder nicht 😉
Der Vortrag diskutiert, warum wir KI-Systeme als soziotechnische Systeme betrachten müssen, um so ein reichhaltigeres Verständnis der sozialen Dimension von Nachhaltigkeit zu entwickeln und zu verstehen, warum KI für den sozialen Zusammenhalt schädlich sein kann.
37C3 – KI – Macht – Ungleichheit. erstellt von media.ccc.de veröffentlicht auf YouTube