Was genau ist generative KI? Der Begriff Künstliche Intelligenz (KI) steht im Zusammenhang mit dem Ziel, Maschinen zu entwickeln, die menschenähnliche kognitive Fähigkeiten aufweisen, wie Lernen, Verstehen und Problemlösen. Begriffe wie Verstehen und Intelligenz sind allerdings missverständlich, denn sie suggerieren einen Grad von menschenähnlicher Intelligenz oder Bewusstsein, der auf die heutigen Systeme bei Weitem nicht zutrifft. Der Begriff maschinelles Lernen (ML) beschreibt das Phänomen treffender und zeichnet ein klareres und spezifischeres Verständnis der Technologien und Methoden, die heute in vielen datengetriebenen Anwendungen eingesetzt werden und die auf statistischen Modellen und Datenanalyse basieren. Das hilft, unrealistische Erwartungen und Missverständnisse zu reduzieren.
Beispiel ChatGPT & Co.
Sprachmodelle (Large Language Modells, LLMs) wie ChatGPT passen sich im Gegensatz zu sogenannten regelbasierten Chatbots (wie Siri oder Alexa in ihren frühen Stadien) bei jeder Konversation weiter an und lernen von ihr, was zu einem persönlicheren und zufriedenstellenderen Nutzererlebnis führt. Das Wort Chatbot erklärt sich von selbst: Du chattest mit einem Bot. ChatGPT ist das aktuell bekannteste LLM, es gibt jedoch noch viele andere, die in unterschiedlichen Entwicklungsstadien stecken. Die Uni Osnabrück stellt ihren Mitgliedern mit kiwi Zugänge unter anderem zu den LLMs von OpenAI zur Verfügung, die auch hinter ChatGPT stecken– und zwardatenschutzkonform (mehr dazu später). Alle LLMs nutzen sogenannte tiefe neuronale Netze, die auf Basis umfangreicher Datensätze trainiert wurden, um Texte zu generieren. Diese Netze nutzen selbstlernende Algorithmen, um Muster in Daten zu erkennen und darauf aufbauend eigenständige Texte zu produzieren. Die Stärke von ChatGPT & Co. liegt in der Fähigkeit, kontextbezogen und kohärent auf Benutzer*innenanfragen zu antworten, was auf eine ausgefeilte Verarbeitung natürlicher Sprache hinweist – das technologische Basiswissen dazu erhältst du bei Interesse in Kapitel 2.
Beispiel DALL-E & Co.
Dall-E ist ein KI-Tool für die Bildgenerierung. Es basiert auf einem ähnlichen Transformer-Modell wie ChatGPT, ist jedoch darauf spezialisiert, Bilder aus Textbeschreibungen zu erstellen. Ein ähnlich bekannter Bildgenerator ist Midjourney. Die Fähigkeiten dieser Modelle beruhen auf der Verarbeitung und Interpretation von Sprache, um visuelle Konzepte zu generieren. Dall-E verwendet beispielsweise fortschrittliche Techniken des maschinellen Sehens (Computer Vision), um realistische und detaillierte Bilder zu erstellen. Die Herausforderung hierbei ist nicht nur das Verstehen der Textanweisungen, sondern auch die Übersetzung dieser Anweisungen in visuelle Elemente.
UPDATE Juli 2025: Mittlerweile gibt es zahlreiche sogenannte multimodale LLMs – multimodal bedeutet: diese Sprachmodelle können nicht nur Text, sondern auch viele andere Dateiformate wie Grafiken oder Sprache als In- und Output verarbeiten. Drei Beispiele sind ChatGPT, Copilot und Gemini, und das bereits in ihrer Basisversion. Sie wurden um viele kleine Extras erweitert, haben aber keine spezifischen Features wie die spezialisierten Bilder- oder Videogeneratoren. Nähere Infos zu multimodalen LLMs findest du auch im zweiten KI-MiMo Expedition KI – Wie textgenerative KI tickt.
Dieses Kapitel hilft dir, Fehlinterpretationen in KI zu vermeiden und KI-Ergebnisse realistisch einzuschätzen. Auf dieser und den nächsten beiden Seiten wird der KI-Hype kritisch, aber unvoreingenommen analysiert. Es geht um populäre Irrtümer, die Evolution der Chatbots und einen Exkurs in Sachen Datensouveränität und Ethik der KI.
ChatGPT in 3 Minuten erklärt
Einige technologische KI-Basics aus dem unten eingebetteten Video werden auf den folgenden Seiten genauer analysiert. Bleib dran, wenn du wissen willst, welche Effekte sie beim Einsatz im Studium haben können. Im Video werden zwei wesentliche Phänomene deutlich, die für ein angemessenes Verständnis künstlicher Intelligenz grundlegend sind:
1. Katzen fressen Gras – und Menschen machen Fehler!
Fressen Katzen Gras? Bei Minute 0:45 wird dies fälschlicherweise als Falsch (Abb. 1) markiert. Natürlich ist es nicht das Hauptnahrungsmittel. Tatsächlich fressen Katzen aber häufig intuitiv Gras, was aus verschiedenen Gründen gut für sie ist, wie du auf der entsprechenden Wikipedia-Seite über Katzengras nachlesen könntest.
Was dieses Beispiel hervorragend illustriert: Menschen liefern regelmäßig inakkurate Informationen – und KIs werden mit diesen gefüttert. Und das ist auch der Grund, warum kein Sprachmodell der Welt allwissend sein kann! Um ein angemessenes Verständnis künstlicher Intelligenz zu entwickeln ist es zunächst einmal ratsam, sich immer vor Augen zu halten, wie viel menschliche Intelligenz tatsächlich hinter KI steckt.
Abb. 1: Fressen Katzen Gras oder nicht?! ChatGPT würde mit NEIN antworten, wäre es nur mit diesem Video „gefüttert“ worden. Da sich u.a. die komplette Wikipedia seinem Trainingsdatensatz befindet, liefert es die korrekte Antwort: JA, Katzen essen häufig Gras.

2. Sprachmodelle besitzen kein eigenes Faktenwissen
Das zweite bemerkenswerte Phänomen besteht in der Tatsache, dass Sprachmodelle keinen eingebauten Faktencheck haben, wie ab Minute 2:09 erläutert wird. Sprachmodelle generieren stattdessen jeweils Wort für Wort, was statistisch am wahrscheinlichsten passt. Dafür gleichen sie Texte aus ihrem Datensatz ab und reproduzieren, was sie im Training gelernt haben – ein Prinzip, das ihnen die Bezeichnung stochastische Papageien eingebracht hat. Wie das gemeint ist, wird auf der nächsten Seite erläutert (Bitte beachte, dass es auf fast allen Seiten noch weitere Tabs gibt, bevor du zur nächsten Seite weiterblätterst).
Was das für den Einsatz im Studium bedeutet? Die von LLMs generierten Inhalte können faktisch falsch sein!
ChatGPT in 3 Minuten erklärt erstellt von youknow veröffentlicht auf YouTube
Der Hype Cycle am Beispiel ChatGPT
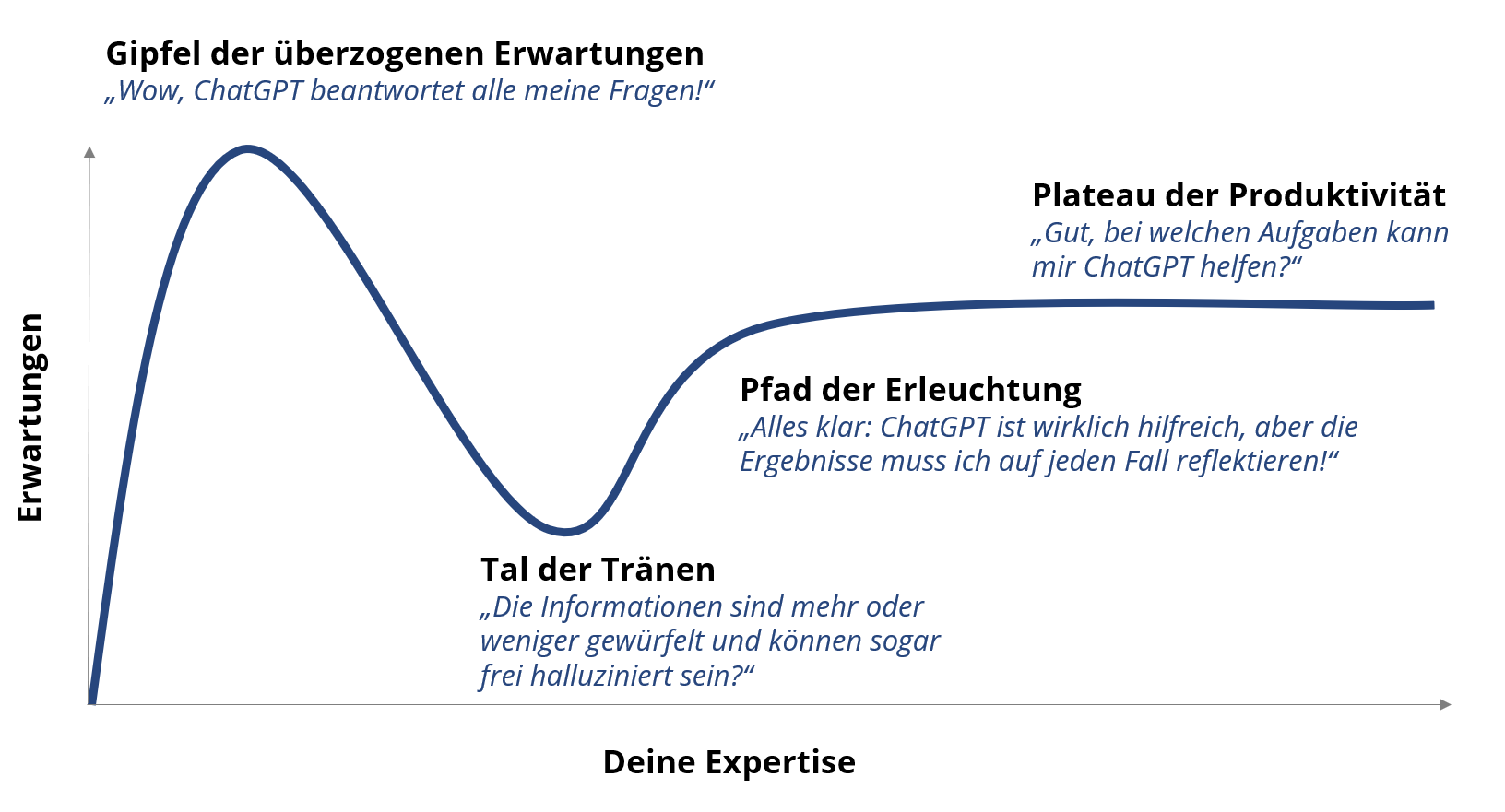
Bei vielen Technologien folgt auf eine große Anfangseuphorie inklusive dem Gipfel der überzogenen Erwartungen das sogenannte Tal der Tränen(Abb. 2). Auf dem Gipfel entstehen oft gravierende Missverständnisse: In Bezug auf ChatGPT zum Beispiel: „Wow, ChatGPT beantwortet alle meine Fragen!“ „ChatGPT ist eine Suchmaschine.“ Warum das falsch ist, erfährst du, wenn du weiter liest.
Im Tal der Tränen könnte es passieren, das dich manche Kritik an künstlicher Intelligenz zunächst verunsichert. Um den Pfad der Erleuchtung einzuschlagen, ist die Analyse dieser Kritik allerdings eine notwendige Voraussetzung, wenn du KI sicher in der Praxis einsetzen willst.
Auf diesem Weg wird klar, auf welcher technologischen Basis LLMs tatsächlich Informationen generieren. Wer diese neue Technologie angemessen reflektiert einzusetzen weiß, hat ein gewisses Plateau der Produktivität erreicht.
Welche Erwartungen in Bezug auf KI sind nun also realistisch? Im folgenden Tab Schwache & starke KI werden zunächst einmal unterschiedliche Grade künstlicher Intelligenz voneinander abgegrenzt, um etwas Klarheit zu schaffen.
Abb. 2: Überzogene Erwartungen vs. eigene Expertise: Wo stehst du? Grafik: Alexander Piwowar
Schwache und starke künstliche Intelligenz
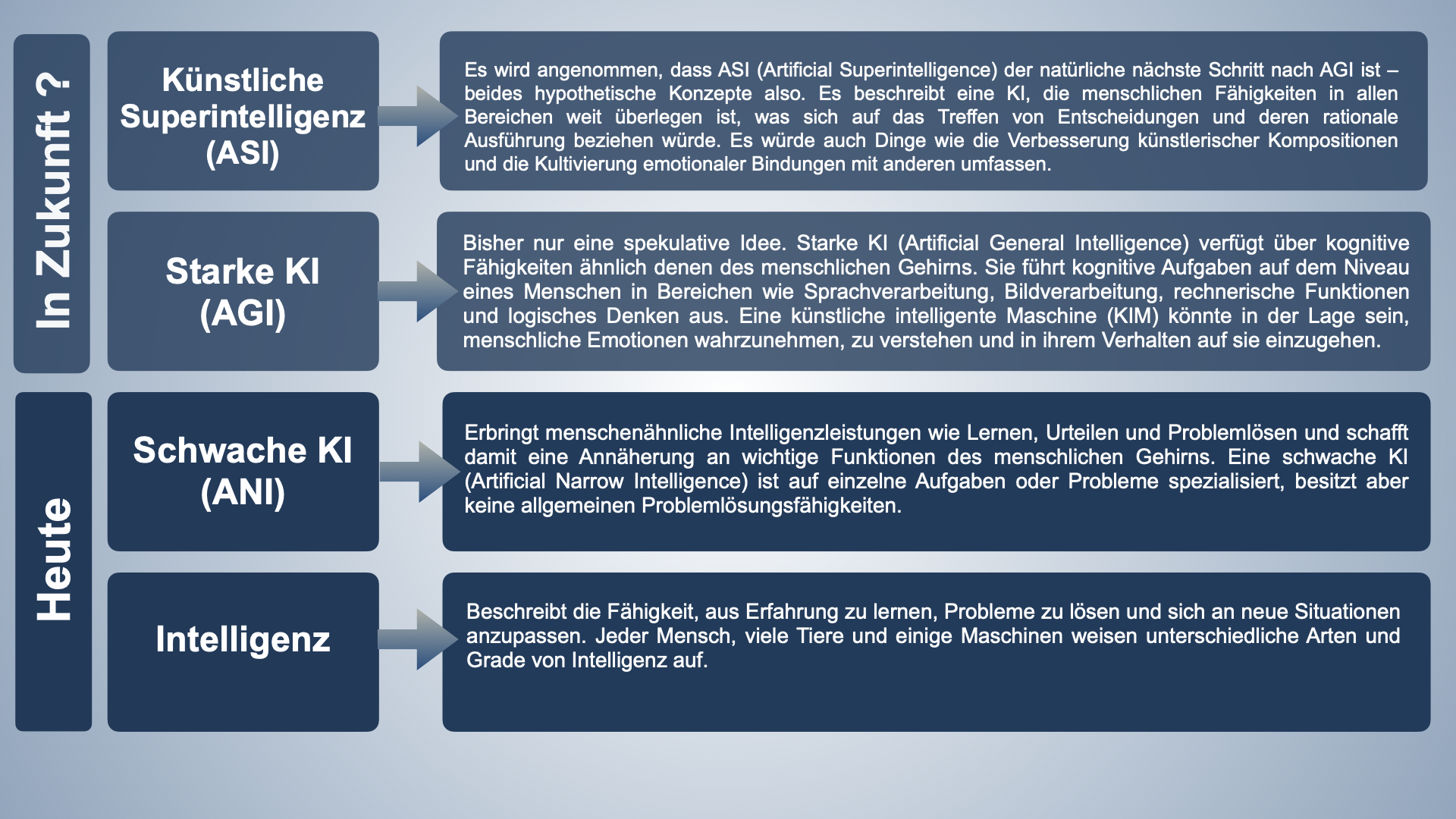
Wie Abbildung 3 zeigt, begrenzt sich das technologische Potenzial aktuell auf sogenannte schwache KI. Beispiele für schwache KI sind viele bekannte Anwendungen wie:
- Spracherkennungssysteme (Siri, Alexa)
- Empfehlungssysteme (Amazon, Spotify)
- Autonom fahrende Autos (Tesla)
Auch Sprachmodelle wie ChatGPT sind schwache KI, obwohl ihnen von einigen bereits menschenähnliche Fähigkeiten zugeschrieben werden. Eine starke KI (AGI) und erst recht eine künstliche Superintelligenz (ASI) sind bislang jedoch Zukunftsvisionen. Forschende von Microsoft haben eigenen Angaben zufolge zwar „Funken von genereller künstlicher Intelligenz“, also starker KI, bei ChatGPT 4 gefunden (Bubeck et al., 2023). Dies ist allerdings nicht nachprüfbar, weil Microsoft die weiteren Details geheimhält.
Abb. 3: Grade von KI – Unterschiede und Zusammenhang der Begriffe. Grafik: Ella Dovhaniuk
Intelligenz intelligent definieren – gar nicht so einfach
Die Gleichsetzung künstlicher Netze mit menschlichen neuronalen Netzen wird von vielen Experten kritisch gesehen (Heuveline & Stiefel, 2021). Auch viele weitere Begriffe, die häufig im Raum stehen, wenn von KI die Rede ist, sind wissenschaftlich bislang nicht eindeutig geklärt. Teilweise sind sie vielmehr Gegenstand philosophischer bzw. metaphysischer Diskurse: Was ist Bewusstsein, was ist Emergenz? Wie in o.g. Forschungsbericht nachgelesen werden kann, stützen sich die Forschenden bei Microsoft auf eine bestimmte, ursprünglich auf Menschen bezogene Intelligenzdefinition. Ebendiese beinhaltet allerdings keine innere Motivation. Eine innere Motivation und damit eigene Ziele zu haben ist allerdings ein Schlüsselaspekt der üblichen Definitionen von starker KI (AGI).
Die dem Bericht zugrundeliegende Definition von Intelligenz umfasst lediglich: Wissen erwerben und anwenden, Probleme lösen, sich an veränderte Situationen anpassen, planen und Werkzeuge zu nutzen bei komplexen Zielvorgaben, die über die eigenen Fähigkeiten hinausgehen. Die Microsoft-Forschenden schränken ein: Dass GPT-4 einen Fortschritt in Richtung AGI darstelle, bedeute nicht, dass es in dem, was es tue, perfekt sei oder dass es annähernd in der Lage sei, zu tun, was ein Mensch tun kann.
Der Begriff künstliche Intelligenz wird auch oft auf starke Rechenleistung, Algorithmen und großen Datenmengen bezogen verwendet. Was Computer wirklich gut können: Mit hoher Rechenleistung und vielen Daten enorm schnell lernen. Statt künstliche Intelligenz ist der Begriff maschinelles Lernen insofern zutreffender und in mancher Situation hilfreicher. Ein paar zentrale Unterschiede zwischen menschlicher und aktueller künstlicher Intelligenz werden auf der folgenden Seite im Detail erläutert und auch auf der Seite Künstliche Intelligenz in ihrem natürlichen Habitat erfährst du mehr.
Was ist „generative“ KI?
Von KI generierte Inhalte werden neu kombiniert und können von menschlichen kaum zu unterscheiden sein. Ebenso wie audiovisuelle Deepfakes können Texte zwar richtig klingen, aber dennoch falsch sein. Für einen souveränen Umgang mit generativer KI müssen wir lernen, die Tools mit sinnvollen Prompts zu steuern und sie reflektiert einzusetzen. Wie es in dem Video heißt: Dann kann die KI die Fleissarbeit machen und der Mensch die Fakten verantworten.
Generative KI in 2 Minuten erklärt erstellt von KI-Campus veröffentlicht auf YouTube
Wenn du es genauer wissen willst: Machinelles Lernen und Deep Learning
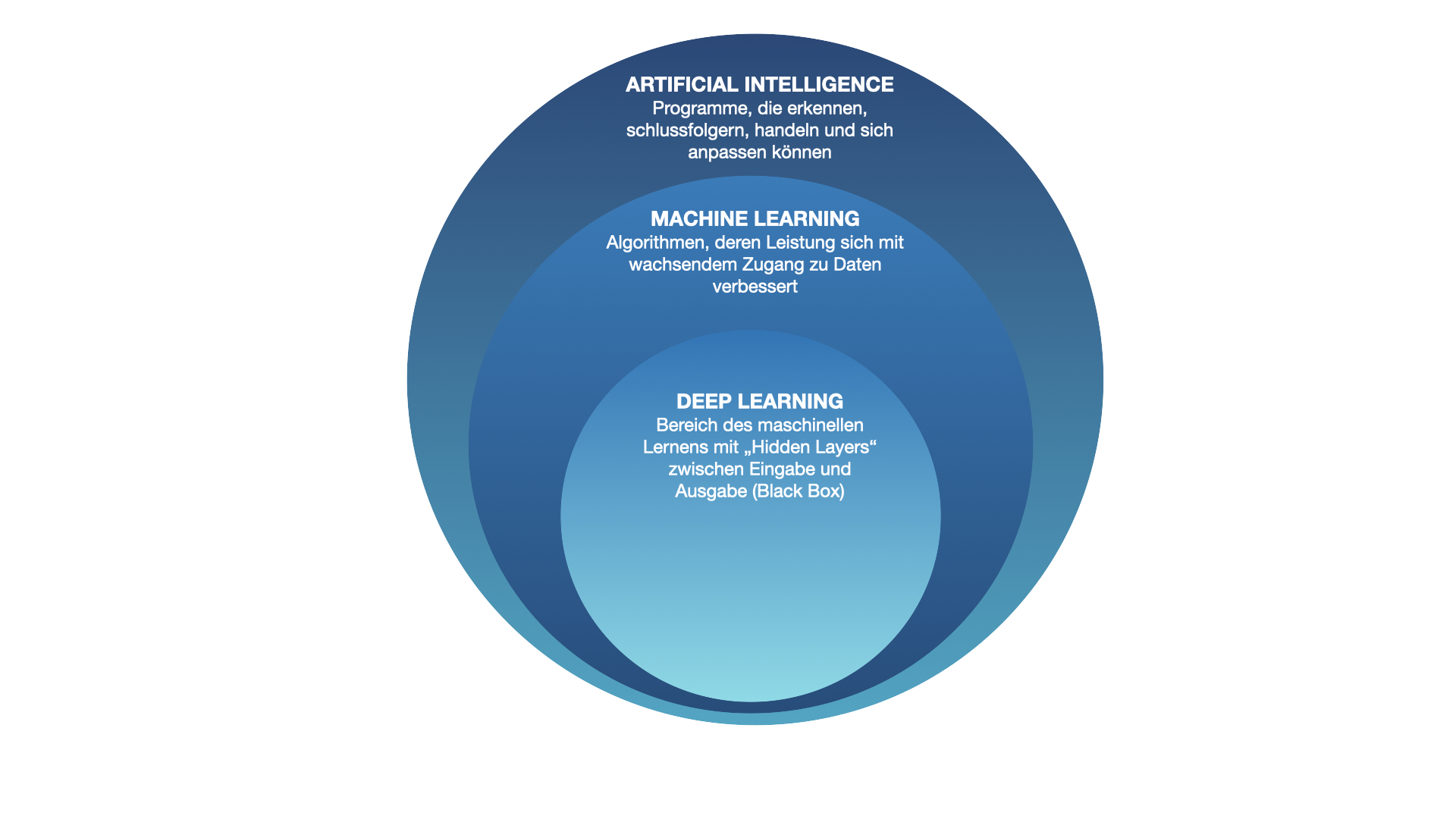
Künstliche Intelligenz ist ein viel und unpräzise verwendeter Sammelbegriff. Der Schlüssel zum Zentrum und somit zum Verständnis der gegenwärtigen technologischen Neuerungen ist der Begriff Deep Learning.
Machinelles Lernen und Deep Learning sind Teilgebiete von KI (Abb. 4). Während KI-Forschung bereits um die 1950er Jahre erste Aufmerksamkeit erlangte, beginnt die Blütezeit von Machine Learning erst Anfang der 80er. Seit den frühen 2010er Jahren haben Durchbrüche im Deep Learning die KI-Forschung zum heutigen technologischen Stand befördert.
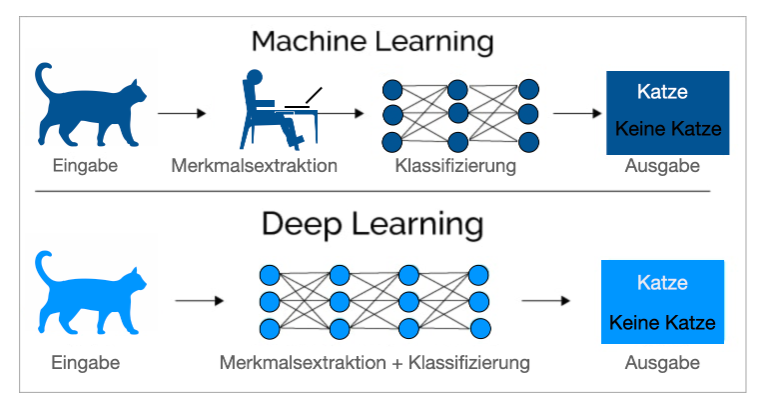
Machine Learning (ML) ist ein übergeordneter Begriff, der sich auf die Entwicklung von Algorithmen bezieht, die aus Erfahrungen lernen und sogenannte Modelle entwickeln können. Ohne dafür im weiteren Verlauf explizit programmiert zu sein, verbessern sie ihre Performance allein dadurch, dass sie mit immer größeren Datenmengen gefüttert werden. Ein Beispiel sind Buchempfehlungen auf Shopping-Websites. Es können allerdings keine unstrukturierten Daten verarbeitet, also z.B. keine Texte, Bilder, Töne, oder Videos in numerische Werte umgewandelt und verarbeitet werden, wie beim Deep Learning.
Feature Extraction, alternativ: Feature Engineering oder Feature Discovery, ist der Prozess des Extrahierens von sogenannten Features aus Rohdaten, um das Training eines nachgelagerten statistischen Modells zu unterstützen. Ein Feature kann zum Beispiel eine Katze sein (Abb. 5). Die Rohdaten – Bilddateien sind ein typischer Anwendungsfall – werden in numerische Merkmale umgewandelt, die mit Algorithmen für maschinelles Lernen kompatibel sind. Beim Deep Learning werden diese unstrukturierten Daten ohne menschliche Eingabe in numerische Werte bzw. Merkmale umgewandelt.
Abb. 4: Deep Learning als Teilgebiet von Machine Learning als Teilgebiet von KI. Grafik: Ella Dovhaniuk
Deep Learning (DL) ist eine spezifische Untergruppe des Machine Learnings, die sich auf künstliche neuronale Netzwerke konzentriert und deren Fähigkeit, tiefe und komplexe Modelle zu erlernen. Sie bestehen aus vielen miteinander verbundenen Schichten von „Neuronen“, die durch viele Verbindungen vernetzt sind – daher „deep“. Diese tieferen Netzwerke haben die Fähigkeit, komplexe Muster und Merkmale in Daten zu erfassen.
Hidden Layers und Black Boxes
Eine der Charakteristiken von tiefen neuronalen Netzwerken im Deep Learning ist, dass man nicht weiß, was genau tief in den sogenannten Hidden Layers passiert. In diesen Zwischenschichten werden automatisch Merkmale aus den Daten extrahiert. Es ist schwierig zu interpretieren – und erst recht genau zu verstehen – wie und warum ein tiefes neuronales Netzwerk zu einer bestimmten Entscheidung bzw. seinen Ergebnissen gekommen ist. Dieses Phänomen wird als Black Box bezeichnet. Es gibt Bemühungen in der Forschung, die Interpretierbarkeit von Deep-Learning-Modellen zu verbessern, um ihre Anwendbarkeit in kritischen Bereichen zu unterstützen.
Abb. 5: Umwandlung unstrukturierter Daten in numerische Merkmale, bei Deep Learning ohne menschliche Extraktion. Grafik: Ella Dovhaniuk